December 2019 alone saw 13,517 submissions to arXiv while an estimate from Nature indicates an 8-9% annual growth in the number of scientific publications.
To alleviate this, researchers need a simple, automated way to find out which publications are relevant for their own areas of research. While some researchers might have their favoured list of authors or publications that they focus on, there is no substitute for scanning the actual content of a publication to determine its relevance. In order to do that in an automated way, we need to make use of Natural Language Processing (NLP). We’ll give a brief overview of some of the techniques in this area and then look at how we’re making use of them in Creme to ease the burden of publication scanning.
Dealing with text data
Machines deal in numbers, so the typical input for any kind of machine learning model is a nice table full of numeric values. Text data doesn’t fit with this so we need to find a way to take a document and convert the words to numbers. There are two broad approaches to this – either we take a whole document and convert to a numerical vector or instead we do this at the individual word level.
In the first approach, we could simply list all the words in our vocabulary and count how often each appears in a given piece of text. Say the word “nutrient” is number 210 in our vocabulary list and it appears 5 times in the article we’re looking at. That article would then have a value of 5 at position 210 when transformed into a vector. Of course, lengthy documents will have higher counts across the board so we typically normalise these values. Even better is to weigh these counts based on the average occurrence of each word across the set of documents that we have access to – an approach called term frequency-inverse document frequency or tf-idf for short.
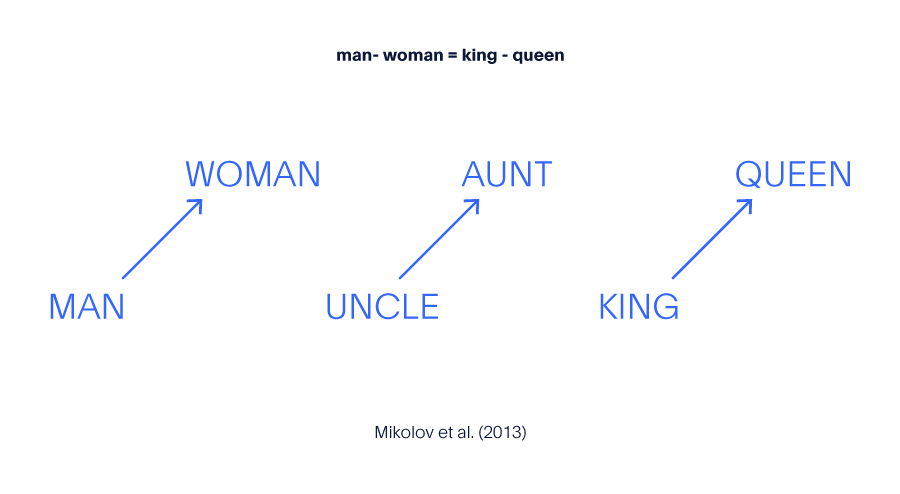
The more elaborate approach is to convert individual words themselves into vectors by embedding them in some high dimensional space. There are many algorithms available for performing this embedding such as word2vec or gloVe and pre-trained embeddings are available off the shelf. These representations are done in such a way that similar words should cluster close together and the difference between words should encode some semantic information. The canonical example of this is:
Text data for machine learning
Once our text has been transformed into a nice numerical vector it’s ripe for the application of some machine learning algorithms. If we need to glean deep understanding at the sentence level we could employ recurrent neural networks such as LSTM which uses word order to identify things like the subject or action in a statement. These powerful algorithms are used in your phones for predictive text or in smart speakers to understand the commands you’re giving.
For things like document ranking word order is less important, so we can simplify things by taking a “bag-of-words” approach – where only the individual terms and their frequencies matter. This approach is still powerful enough to perform document classification, sentiment extraction or topic modelling.
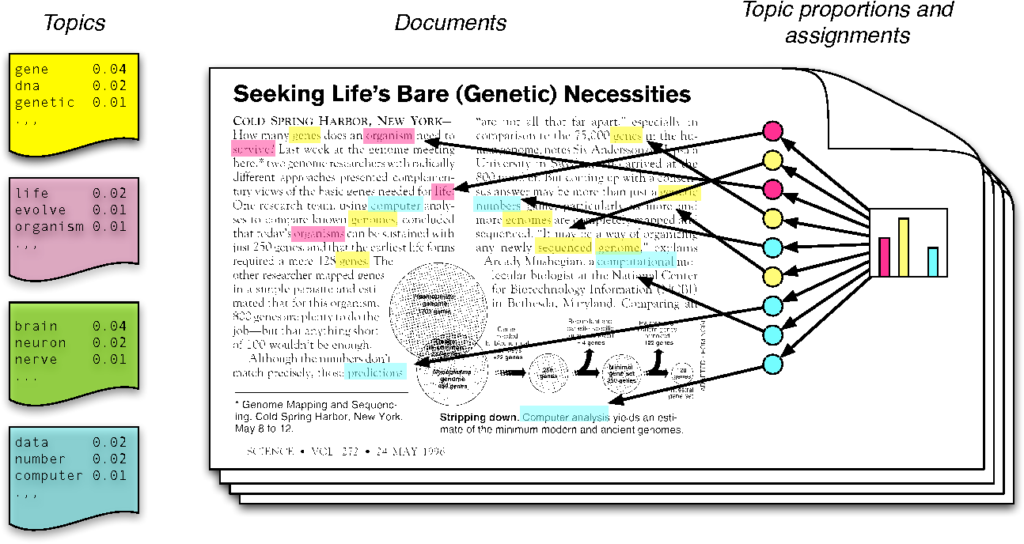
Topic modelling, for example, is a way to find a higher level of abstraction from a piece of text and to identify the broad set of topics that the text is discussing. There are two ways to think about this – one is to start from the high dimensional vector representation of a document and to use dimensionality reduction to project this to a smaller set of dimensions. If we project to 10 dimensions say, we could think of these as encoding 10 different topics. Words will project more strongly onto different dimensions depending on how relevant they are to that topic. The other way this is done is from a probabilistic approach – we think of writing a document as first sampling from a distribution of topics that the document will address and then, based on that selection, sampling a word associated to that topic. Each word is then selected in this manner.
There are numerous types of hazards and exposures which we face in the products and food we interact with every day – each one with an associated severity of effect (harm) and likelihood of occurrence. Here are some elements to consider.
Blei (2012)
Document ranking
So let’s go back to the problem of identifying relevant research and see how NLP can help.
For starters, even relatively simple statistical measures like tf-idf can be used to identify documents where a search term that we’re looking for appears with a higher frequency than expected. So in this way we don’t just find publications that match our search terms, we also find the ones with the greatest emphasis on them and can therefore rank the results accordingly.
If we want to get a bit more sophisticated we can instead employ some topic modelling and search for a topic rather than just a few search terms. By targeting whole topics rather than words we can broaden the scope of our search and make sure that we identify research that addresses the areas we care about – even if they don’t contain the search terms that we would normally look for.
Next steps
Working with our partners we’re continuing to expand our capabilities to help researchers keep abreast of the latest publications that matter to them. Contact us to find out more about our work in this space.
References
- https://arxiv.org/stats/monthly_submissions
- Landhuis, E. “Scientific literature: Information overload”. Nature 535, 457–458 (2016) doi:10.1038/nj7612-457a
- Mikolov, Tomas, Wen-tau Yih, and Geoffrey Zweig. “Linguistic regularities in continuous space word representations.” Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. (2013)
- http://colah.github.io/posts/2015-08-Understanding-LSTMs/
- Blei, David M. “Probabilistic topic models.” Communications of the ACM 55.4 (2012): 77-84


